Unleashing the Power of Unstructured Data
- Date: May 04, 2023
- Read time: 14 minutes

Protecting and managing unstructured data requires a different approach.
For nearly 15 years, Superna has been dedicated to solving problems around the fastest growing, most complex data set on the planet…unstructured data. What is unstructured data? It’s a Storage Administrator and Security Officer’s nightmare – images, audio, video, emails, texts, presentations, patient records, contracts, social media content, Internet of Things (IoT) data, streaming data and the like.
When we talk about unstructured data, the concept of “data gravity” seems appropriate.
When we talk about unstructured data, the concept of “data gravity” could never be more appropriate. Typically, when people talk about data gravity, they’re not talking about a 1 terabyte database… they’re talking about petabytes or zettabytes…or even exabytes. Most devices, services and analytics tools we use today across all business verticals and day-to-day life are contributing to this data footprint at an unprecedented rate!
How big is it, and how fast is it growing?
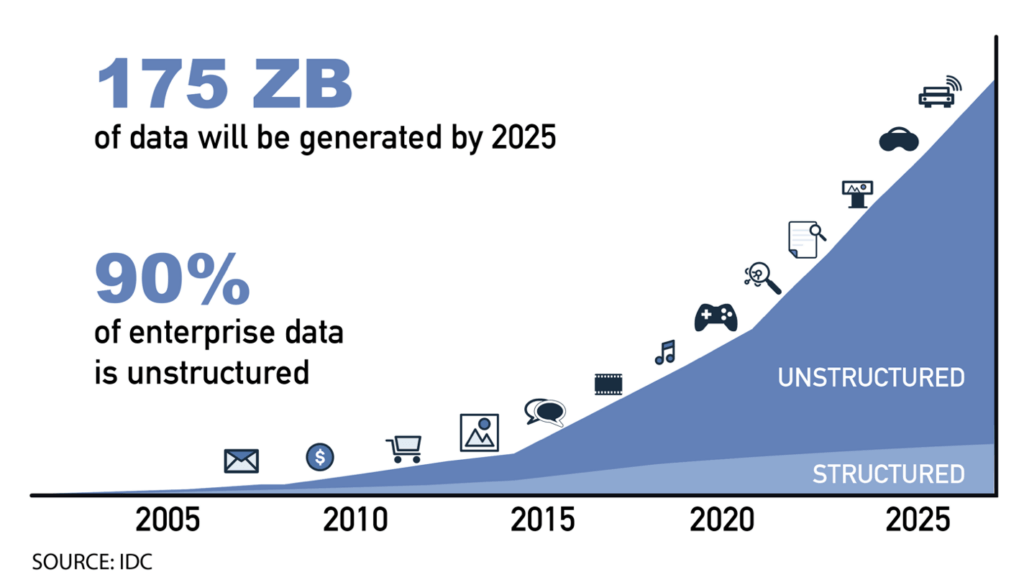
The amount of digital data out there in the wild right now is constantly growing, and while it’s difficult to provide an exact number, a report by Seagate estimated that, as of 2021, the total amount of data created, captured, copied, and consumed in the world was around 59 zettabytes (1 zettabyte = 1 trillion gigabytes). Remember when having a “gig” of data on your mobile phone was a big deal? No? Well, I guess that confirms how much older I am than you. I remember having 250MB for computer storage was “next gen”. Anyway, that data footprint continues to grow rapidly, with IDC suggesting that the total amount of data in the world will reach more than 175 zettabytes by 2025!
A couple of things to consider about the nearly 60 zettabytes of “current” data:
- 90% of all the digital data on the planet is comprised of unstructured data… that amounts to more than 53 zettabytes!
- Roughly 80% of all the data on the planet is currently unprotected!
So, when we talk about traditional structured data and databases – relational SQL-based databases such as Oracle, MySQL, and Microsoft SQL Server, and NoSQL databases like MongoDB, Cassandra, and Redis – remember that they represent only a fraction of the data that’s out there. For the most part, that data is already being protected to some degree. But the far bigger chunk of “data in the wild” is unstructured data. Most of this data remains completely unprotected when compared to the traditional methods of structured data protection. Worse still, far too many organizations don’t have even the slightest clue as to exactly what they’re holding in terms of their unstructured data, let alone how to manage it.
So what if I don’t protect or understand my unstructured data. Does it matter? It does… more now than ever!
In the beginning…
Unstructured data has traditionally been either one of two things:
- The filesystems that contained all your company’s critical information, employee data, customer data and intellectual property
- The object storage dumping ground that contained all the “stuff” that you thought you needed to keep, you may not have been 100% sure why you needed to keep it, but you kept it anyway
And, from the beginning of “tech times,” this data grew…and kept growing. In the beginning, there were a handful of unstructured data platforms. We had the rise of Dell, NetApp, Qumulo and a few others who took the unstructured data challenge head-on (and have the earnings and customer footprint to prove it). The concepts for attacking the data growth and data complexity challenges gave birth to other companies, also mostly focused on on-prem storage. Soon, cloud providers got into the game with platforms for filesystems and object storage and, over time, we saw the on-prem players delivering their own unstructured data platform experiences in the public cloud. Next, we saw the rise of distributed file systems, essentially taking a software-defined approach to the access and mobility challenges which had traditionally been solved with hardware solutions. At this point, even those distributed systems have planted their proverbial footprints into the multi-cloud arena. Why? Because the data monetization opportunity is on our doorstep.
Growth feeds opportunity; opportunity feeds innovation
QUESTION: When you have zettabytes of complex, heavy data, that nobody has traditionally paid attention to, growing at 55-65% per year, when would you need to start paying attention to it?
ANSWER: When the applications and services you want to leverage start working with it.
But before going any further, it’s important we separate this into the two sides of this evolutionary story: Unstructured Data Platforms and the Unstructured Data itself.
Unstructured Data Platforms – Taking Advantage
Remember when Amazon S3 was the data abyss where you said you kept stuff for compliance reasons? Well, times have changed. The investment that’s gone into unstructured data platforms like object storage has not only made them “cheap and deep,” but has also provided a series of cost-effective options that have impressive data recall. When considering the price of traditionally high iOPS platforms, some customers are realizing that there is an alternative for their data access, data protection, and data analytics workflows. It just so happens these storage platforms are 20%-30% the price of the high iOPS, high access platforms which, in the end, might not be necessary for their data requirements.
Some application environments, even complex ones like SAP, are taking this to the next level. If you look at some of the refactoring work that’s happening with SAP’s move to HANA, the in-memory database will cost you more in memory but may afford you the financial luxury of cost-effective object storage as a primary storage architecture. Yes, you heard me, object storage as a primary storage architecture.
Distributed teams working on large, complex files across a myriad of platforms is becoming more common than you think. The notion of going back-and-forth – from file to object and object to file – for distributed teams, is a table stakes workflow across multiple industries. The Media and Entertainment vertical set the stage, but now, we’re seeing it across Financial Services, Healthcare, Insurance and Education, as well.
I can’t put copies of structured data onto unstructured data platforms, though, right? Wrong. Suspend your disbelief, but yes… yes, you can. In fact, one of the growing trends among customers is the creation and storage of hyper-granular, virtual copies of structured data (like traditional databases) on object storage platforms. The cost effectiveness of the platform enables storing structured data instances every 5, 10, 15 minutes – in object storage. In this way, customers are getting the benefit of structured data storage, in very tight increments, with low-cost per terabyte and fast recall. If you’re ticking the box from a data protection perspective, you’re now able to do so in some very cost-effective ways.
Unstructured Data: Unleash the Beast
OK, let’s talk about the data itself. Today, 50% of the data that goes into Artificial Intelligence, Machine Learning, and Business Intelligence applications is unstructured. That’s a 300% increase from only two years ago, when it was closer to 15%. That said, that 300% increase still only represents 1% of the total unstructured data footprint. Of course, once you start talking about ChatGPT and AI, the equation changes. Would you like to guess what percentage of the data output by AI, ML and BI is unstructured? It’s actually 100%!
Take Healthcare, for example. All over the world, you’ve got labs and hospitals that are crunching data and analytics. The output of that crunching is all unstructured data. So where does it go? It goes back into some kind of unstructured data storage. And if you crunch it again? That also goes into your unstructured data storage – and the cycle continues. I can’t tell you how many customers we’re working with in Healthcare, Pharmaceutical, Insurance and Financial Services that are crunching data and dramatically growing their own footprints by finally monetizing their unstructured data. While this is EXCELLENT from a value creation perspective, if you don’t have a strategy for distributing and managing that, across your on-prem and cloud environments – you’re basically burning cash on both sides. It’s frightening!
And it’s not just Healthcare. Unstructured data is foundational for the AI and ML innovations coming out of companies like Microsoft, Google, and IBM. Whether it’s driverless cars and boats or Natural Language Processing (NLP), unstructured data is at the core of learning from and teaching the AI and ML algorithms that are increasingly influencing our lives. Of course, the obvious reality of this cycle is what I alluded to earlier: Growth… massive, massive growth. So now, what was once a seemingly bottomless pit of mostly unused data has morphed into a goldmine that can be utilized in more and more ways. Data Analytics services and companies have made significant investments in their platforms to ingest a higher and higher percentage of unstructured data. Data Leaders are in a unique position to be the “hero” that monetizes data, while solving for the strategy to deal with this unprecedented growth.
So, what’s holding you back?
So, with lots of data to work with and more analytics and BI tools able to work with unstructured data, what’s the hold up? In short:
- Where your data currently resides may not be the most cost-efficient location
- Where your data needs to be processed is frequently nowhere near where it resides
- Securing unstructured data is a daunting task that can expose petabytes to various flavors of Ransomware, Exfiltration and Untrusted Access
- Providing Audit and Forensics capability across complex object and filesystem landscapes is not just finding a needle in a haystack… it’s more like finding a needle in a stack of needles.
- These realities translate into a set of questions that today’s Data Strategy Leaders are asking constantly, thoughtfully, and relentlessly as they evolve how they work with the largest digital footprint on the planet:
“Are my data platforms and my costs aligned?”
The answer is pretty much always “no”.
“How did that happen?”
I can’t tell you how many times we’ve been on the phone with a prospective customer and their opening statement is: “I was here yesterday, and the SMB shares were here, the files were here, the data was here. But I came in today, and I had a whole bunch of internal clients asking me where it was, and I had no idea. I don’t know where it is. Can you help me? Can you find out where it went?”
“Did it even happen?”
One of the popular threats nowadays is just that… a threat. Sometimes, cybercriminals send messages into a company saying “I’ve got my hands on your customer data…” or maybe customer data from XYZ environment… “And I’m going to leak it. Here’s where you need to send your tokens.” And sometimes in these situations, the user is telling us “I don’t even know if this breach actually occurred! I have no way of knowing if someone actually got hold of any of our data!”
How does Superna address these challenges?
When it comes to addressing the above, we take a three-pronged approach.
The first is through providing intelligent orchestration to simplify ongoing management of what is typically a really challenging platform and set of data footprints.
The second is to provide support for forensics and compliance: “Who touched what?” We’re basically looking to determine who is accessing the data, and what – if anything – has actually happened to that data.
Finally, we apply the NIST cyber security framework to the largest and most complex data layer on the planet. We provide our customers with much more insight and control and run security at the data layer itself. This is a huge differentiator for us.
Intelligent Data Orchestration – not just Backup
If you’re running an IT organization, we all know that backup is table stakes. Some organizations have 2, 3, even 4 backup solutions, perhaps running across different lines of business or different functions. In 2023, with Data Compliance Regulations as they are, you’ve got to be able to make a copy of data (sometimes even an additional air-gapped copy); you must have a backup copy and you need to be able to seamlessly recover that backup or air-gapped copy.
That said, a growing data footprint cannot be addressed by backup alone. Whether your data growth is organic or is a byproduct of analytics and monetization, it will become critical to understand which data should go somewhere else… maybe it’s accessed less frequently or barely at all. When you get to the point where you need to shift your data strategy from backup and copies to Intelligent Orchestration, you need to be able to understand exactly who is touching what data, and when. That knowledge opens the aperture of data movement and archive possibilities – from lower cost options on premise, to deep archive tiers in the cloud that could cost you pennies on the dollar.
Once empowered with the knowledge of what data can go where, then you need the mechanism to move that data – not just copy it, but MOVE it into whichever tier or service that you want to. Imagine taking a multi-petabyte pool of data and having full orchestration control; making a copy of it for compliance / recovery purposes); segmenting it based on access patterns, frequency and purpose. This gives you the power to be compliant, reduce spend, and monetize!
This is how we close the gap. It looks easy – but auditing, moving and securing complex, unstructured data at petabyte scale is challenging, and it’s where we’ve spent nearly 15 years of engineering to perfect it!
Prevention is the New Recovery
Nowadays, you need to be able to detect when someone – internal or external – is accessing your data. This is not only critical for audit purposes, but access can also be the initial indication of trouble. Untrusted access or strange data access patterns are often associated with the initial stages of Ransomeware or Exfiltration. As an example, a couple months ago, Royal Mail was hit with LockBit. As their files were being encrypted, it created a pattern – this pattern is recognizable. At Superna, our software detects several hundred unusual patterns, and we are constantly adding capabilities around virus strains and emerging threats. When it comes to our customers, we frequently will detect when a burrowing event or activity suggestive of ransomware is taking place. More specifically, if we were to observe an attack like LockBit, we would detect the anomaly and, can trigger an air-gap of data and loc- out the IP address that posed the threat. This is the next level of security, and it runs specifically at the data layer.
Sometimes, the threat you face is an internal bad actor who already has access to your network. Because we have an AI learning layer that’s looking at data access patterns, we can detect when a person operating at the data layer is behaving in a way that’s “outside of the norm.” So, when someone who normally accesses certain data environments is now touching seven other shares, maybe making copies of them, or conducting what looks like mass deletes, their access can be frozen and they can be locked-out. We’re in the process of evolving this capability to trigger action via a SOAR security automation framework. One of the first integrations we’re launching is with ServiceNow. In many cases, our security presence at the data layer is the last line of defense, but in some cases, we might be the first line of defense, detecting what could – if left unchecked – become worse… much worse.
Superna knows unstructured data
At Superna, we’ve positioned ourselves at the forefront of unlocking these large, complex unstructured data footprints. We work closely with the platforms themselves to help ensure that our customers are empowered to copy, move, audit and secure their most precious commodity: their data. And after nearly 15 years of thoughtful engineering and tireless commitment, we’ve successfully solved for the security, audit and orchestration challenges of the largest digital data footprint on earth: unstructured data.
Featured Resources

Mastering Cybersecurity Insurance Negotiations: A Comprehensive Guide

Navigating the Digital Menace: A Beginner’s Guide to Ransomware
