Securing Your Data Pipeline in the Era of AI and ML
- Date: May 10, 2024
- Read time: 10 minutes


Overlooking data security and data lifecycle can create vulnerabilities in the infrastructure that supports your AI and ML Initiatives.
Background
As interest in Artificial Intelligence and Machine Learning (AI and ML) has exploded, data security and data lifecycle are frequently overlooked when building out infrastructure for AI/ML initiatives. We’ll look at some of the challenges and considerations around securing AI/ML workloads, along with Superna’s approach to providing data-layer security and how it can help close the security gap left by traditional data protection solutions.
Overview
The key components of an AI/ML infrastructure include:
- Host Compute
- GPU Training/Inferencing
- File Storage and Object Storage, combined into an architecture that supports a data pipeline.
Let’s look at a typical set of functional steps that are needed and then review which ones require consideration for data life cycle and security requirements.
Functional Stages for Building & Securing an AI/ML Data Pipeline
Data Collection
- Gathering data from various sources such as databases, online servers, APIs, sensors, and more. This is the foundational step where you obtain the raw material for your analysis and model training.
- Data Lifecycle Considerations
- Is your source data current? How old is the data?
- Are you able to scan your dataset and break it down by age and by type of data, in order to provide a summary of average age, ownership, and type of data used in the early stage?
- Data Security Considerations
- Who is modifying this data?
- Can you report on users who have modified any of the potential training data before it’s used? This is a data governance “best practice” that allows you to trace the origin of the data used in your AI model.
Data Cleaning and Preprocessing
- Cleaning data allows you to remove inaccuracies, errors, or irrelevant information. This can include handling missing values, correcting data types, and removing duplicates.
- Preprocessing might involve normalizing or scaling data, encoding categorical variables, and possibly data augmentation techniques to enhance model training
- Data Life Cycle Considerations
- Data Versioning allows snapshots to create multiple views of the data in a space efficient manner. Each view can build on the same source data set but apply cleaning, or preprocessing steps without modifying the original data set.
- Superna’s DR Edition automates writable snapshots, enabling a point-and-click method for generating on-demand, space-efficient views of the source data set, to validate the preprocessing before committing the modifications to the source data set. Simply delete version snapshots of source data to roll-back or permanently delete that view of the data.
- Data Security Considerations – Superna DR Edition has role-based security, allowing your AI/ML data scientists to create controlled versions of the dataset using a dedicated role within the DR Edition. It automatically generates a complete audit trail of these actions for security and traceability, covering all changes made to the training data.
Data Exploration & Analysis
- Performing statistical analysis and exploratory data analysis (EDA) to understand patterns, trends, and correlations within the data. This step helps in gaining insights that can guide further processing and feature engineering.
- Data Life Cycle Considerations – During this phase, the data has been preprocessed and is ready for analysis. Making offsite backups to protect this phase of the data at stage 1 of the data pipeline is critical. Superna Data Orchestration Edition can make an incremental-always copy of Stage 1 ML data to offsite S3 buckets, preserving the data pipeline before further staging changes the dataset. As data is updated by your data scientists, each update is synced from the file system to the offsite S3 bucket.
- Data Security Considerations – Superna Data Security Edition enables any manipulations made by your data scientists to be tracked and traceable, resulting in a Zero-Trust data pipeline. This is achieved by logging all data manipulations, by user and by time stamp for both historical reporting and forensics.
Feature Engineering
- Create new features from existing data in order to improve the performance of ML models. This might include selecting, modifying, or combining existing features based on insights gathered in the previous step.
- Data Life Cycle Considerations – The same backup requirements exist any time a phase updates or makes changes to training data.
- Data Security Considerations – The ability to trust the inputs to an AI model starts with a chain-of-custody of all data manipulations. Superna Data Security Edition allows end-to-end chain-of-custody reporting and analysis.
Data Splitting
- Dividing the data into training, validation, and test sets helps ensure that the model trains effectively and generalizes well to new, unseen data.
- Data Life Cycle Considerations – Data backup of modifications to the data is important to this phase of the AI/ML pipeline; Superna Data Orchestration Edition meets all the requirements needed to protect the pipeline.
- Data Security Considerations – Trusting the inputs to an AI model starts with a chain-of-custody of all data manipulations. Superna Data Security Edition meets the requirements for this phase of the AI/ML pipeline.
Model Training
- Apply ML algorithms to the training data to build models. This step involves selecting a model, configuring its parameters, and iteratively training it on the data.
- Data Life Cycle Considerations – This phase of the AI/ML pipeline requires multiple iterations, with the test-run output requiring offsite protection to allow full root cause traceability of test-runs to test outputs. Superna Data Orchestration Edition enables the backup-and-restore of test training runs with different versions of the training data backed-up from previous stages of the pipeline. In addition, Superna DR Edition allows on-demand, writable snapshots to prevalent editable views of the training results without affecting the master test run. Rapid training runs, reviewing, and analysis are critical steps for accelerating the AI/ML process.
- Data Security Considerations – This stage of the AI/ML process is where trust is of utmost importance to avoid manipulation of training data that could influence the training model (see this blog post on AI/ML training data attack vector proof-of-concept). This stage requires backups with Superna Data Orchestration Edition on each training run in order to preserve a copy of the data that was used to build the training model. It also enables chain-of-custody traceability of who “touched” the training data. Superna Data Security Edition allows for chain-of-custody reporting, along with reporting on malicious user activity that could affect the integrity of a model built from a given set of data. This requires real-time monitoring of data manipulation by users and applications. Remember: your AI models are only as good as the data used to build the model.
Model Evaluation
- Assess the performance of the model using the validation set (and later the test set) to measure accuracy, precision, recall, F1 scores, and other relevant metrics. This helps in determining the effectiveness of the model along with whether or not it meets the project’s objectives.
- Data Life Cycle Considerations – No special considerations
- Data Security Considerations – No special considerations
Model Tuning and Optimization
- Refine the model by tuning its parameters (hyperparameter optimization) or choosing different modeling techniques based on the performance metrics. This could also involve feature selection and re-engineering to enhance model outcomes.
- Data Life Cycle Considerations – Each test run that produces a new model is a point-in-time that needs to be protected offsite, in the event that a version of the model needs to be restored to root cause an issue. This is where a version-aware, file-to-object incremental backup would need to be continuously running in the background. Superna Data Orchestration Edition can perform version-aware backups/restores using S3 versioning and incremental backup process.
- Data Security Considerations – The data on the file system needs real-time and historical user and application protection policies. Superna Data Security Edition provides both requirements along with Zero-Trust backup integration into Superna Data Orchestration Edition. This helps ensure that backup data is not compromised by malicious data manipulation of the training data. The backup process is designed to automatically stop if a threat is detected on the source file system. Data security of the source data is not the only weak link in the data pipeline. The backup data could be manipulated and the dataset restored for future training or modeling. This risk is mitigated by Superna Data Security Edition for Object that monitors the S3 backup data in real time, for any malicious data activity that could compromise the backup data.
Model Deployment
- Deploying the model into a production environment allows it to start making predictions or decisions based on new data. This step often involves integration with existing systems and setting-up a process for continuous monitoring and updating.
- Data Life Cycle Considerations – The final version that exists of the data pipeline needs special protection consideration i order to create an immutable offset copy. This can be accomplished with Superna Data Orchestration Edition, which has the ability to integrate with Object-lock capabilities in object storage that will make a locked copy of the final training files, model files that will be moved into production.
Monitoring and Maintenance
- Continuous monitoring of the model’s performance over time allows it to catch and correct any drift in predictions or changes in data patterns. Regular updates and maintenance are necessary, in order to keep the model relevant and effective.
- Data Life Cycle Considerations – No special considerations
- Data Security Considerations – No special considerations
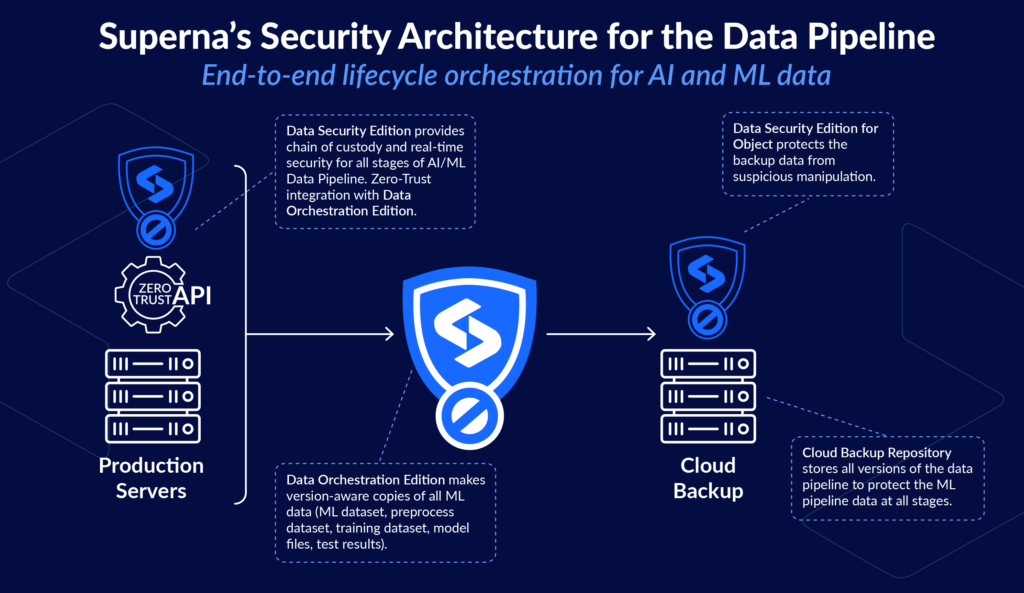
Superna Data Pipeline Security Architecture
Superna offers an end-to-end backup and security solution that covers each phase of an AI/ML data pipeline, from when data initially enters the system through each subsequent stage of the data pipeline. It’s available as a file- and object-aware solution, with tight integrations between data orchestration and security of the file and object data stores.
Summary
Your AI/ML data pipeline requires a data lifecycle and security strategy that helps ensure the integrity of the model. It must be verifiable from the initial data ingest stage all the way through to the production model. As of today, regulatory requirements do not yet exist for how AI algorithms and models are built and verified, but that time may well arrive sooner than later.
Designing a complete data lifecycle security strategy at the outset will help ensure your AI/ML project is both tamper-proof and future-proof. If your AI model does not perform as expected – with no ability to root cause which stage of the pipeline has been corrupted – your company’s reputation is at risk. Having the ability to restore any version of the data pipeline and validate each change made by authorized individuals is crucial to building a trustworthy AI model.
Prevention is the new recovery
For more than a decade, Superna has provided innovation and leadership in data security and cyberstorage solutions for unstructured data, both on-premise and in the hybrid cloud. Superna solutions are utilized by thousands of organizations globally, helping them to close the data security gap by providing automated, next-generation cyber defense at the data layer. Superna is recognized by Gartner as a solution provider in the cyberstorage category. Superna… because prevention is the new recovery!
Featured Resources

Mastering Cybersecurity Insurance Negotiations: A Comprehensive Guide

Navigating the Digital Menace: A Beginner’s Guide to Ransomware
