Exposure Scoring 101: Why Traditional Exposure Platforms Cannot Measure Data Risk
- Date: Dec 31, 2025
- Read time: 6 minutes


And Why Data Attack Surface Management (DASM) Is Required for Real CTEM Outcomes
Why Measuring the Data Attack Surface Is Different Than Measuring Exposure
Unstructured data continues to grow faster than security teams can inventory, classify, or govern. At the same time, enterprise environments have become more complex—nested identity groups, service accounts, inherited permissions, shared storage platforms, and hybrid architectures now define how data is accessed.
Attackers understand this reality. They do not exploit individual vulnerabilities or misconfigurations in isolation. They exploit systems of exposure—where access paths, behavioral blind spots, permission drift, and sensitive data converge into viable attack paths.
This is why measuring exposure at the data layer cannot be treated as an extension of traditional exposure assessment. Data risk is not infrastructure risk. And attempts to assess it using the same models inevitably fail.
The Core Limitation of Traditional EAP Platforms
Exposure Assessment Platforms (EAP), including vulnerability-centric, identity-centric, and infrastructure-centric tools, were designed to answer a different question:
“What can be reached?”
They were not designed to answer:
“What data is at risk, how meaningful is that risk, and how likely is it to be exploited?”
This distinction is critical.
Most EAP platforms focus on:
- CVEs and exploitability
- Identity reachability
- Network paths
- Cloud configuration states
- Entitlement graphs
Even when these platforms introduce “AI,” they are constrained by a hard limitation:
AI can only reason over the data it is given.
If the platform does not ingest data-layer context, no amount of AI will produce a true data risk assessment.
Why “Adding AI” to EAP Does Not Solve the Problem
Many EAP vendors claim to apply AI or machine learning to exposure scoring. In practice, these models operate over non-data-aware inputs, such as:
- Asset criticality tags
- Identity relationships
- Vulnerability metadata
- Infrastructure configuration states
This creates a false sense of intelligence.
AI on Incomplete Data Produces Confident—but Wrong—Results
Because traditional EAP platforms do not have access to core data risk signals, their AI models cannot account for:
- What the data actually contains
- Whether the data is sensitive, regulated, or business-critical
- How the data is used over time
- Whether access patterns are normal or anomalous
- Whether permissions are excessive relative to usage
- Whether the data itself is stale, corrupted, or overexposed
As a result, these platforms:
- Over-score benign access to low-value data
- Under-score exposure to highly sensitive datasets
- Treat all access as equally risky
- Confuse theoretical reachability with real attack potential
This is not a tuning problem. It is a data model problem.
The Fundamental Blind Spots of Traditional Exposure Platforms
No matter how advanced the scoring logic or AI layer becomes, EAP platforms lack the inputs required to assess data risk accurately.
What Traditional EAP Platforms Do
Not
Understand
Most exposure platforms do not ingest or reason over:
- Data sensitivity
(PII, PHI, financial data, IP, regulated content) - Data classification results
(what the data is, not just where it lives) - Data overexposure
(how broadly sensitive data is accessible relative to need) - Data over-permissioning
(access rights that exceed observed usage) - User and service account behavior at the data layer
(who actually touches the data and how) - Access pattern deviations
(volume, frequency, path anomalies) - Data quality and integrity signals
(stale data, orphaned datasets, abandoned shares) - Protection state of the data itself
(air gap, immutability, recovery posture)
Without these signals, true data risk cannot be calculated, only approximated.
Why Static Scoring and Weights Fail at the Data Layer
Traditional exposure scoring relies on fixed weights applied to predefined factors. This approach assumes:
- Risk is linear
- Inputs are independent
- Context can be normalized
- Scores remain valid over time
None of these assumptions hold true for unstructured data environments.
At the data layer:
- Risk emerges from combinations of signals
- Context changes continuously
- Permissions drift silently
- Behavior matters more than configuration
Static weights cannot capture:
- When access is risky only because the data is sensitive
- When behavior is dangerous only because it deviates from baseline
- When permissions matter only because they are unused or excessive
As a result, traditional scoring systems collapse complexity into oversimplified numbers that do not map to real-world risk.
Why Data Attack Surface Management (DASM) Is Fundamentally Different
Superna Data Attack Surface Management (DASM) starts from a different premise:
Risk must be measured where the data lives, using data-aware context.
DASM treats data as the primary attack target—not an attribute of infrastructure.
DASM Data Inputs: What True Data Risk Assessment Requires
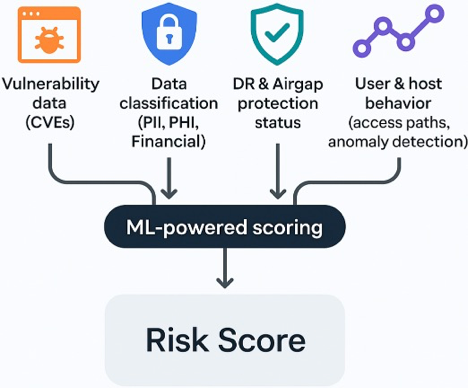
Unlike EAP platforms, DASM ingests and correlates data-native signals, including:
Core DASM Input Domains
1. Data Sensitivity and Classification
- PII, PHI, financial, regulated, and business-critical data
- Content-aware classification signals
- Sensitivity-weighted impact modeling
2. Data Access and Permission Context
- Share-level and file-level permissions
- Inherited and nested group access
- Over-permissioned and unused access paths
3. User and Service Account Behavior
- Actual access patterns over time
- Role-consistent vs anomalous usage
- High-volume or abnormal interaction patterns
4. Data Overexposure Signals
- Broad access to sensitive datasets
- Dormant data with lingering permissions
- Misalignment between usage and access breadth
5. Protection and Resilience Context
- Air gap and DR posture
- Recovery readiness
- Protection gaps that amplify impact
6. Environmental and Operational Context
- Storage platform characteristics
- Integration with adjacent security signals
- Change events that affect exposure
Why AI Works in DASM—but Fails in EAP
The difference is not the algorithm.
It is the inputs.
DASM applies ML and AI inferencing after data-layer context is established. This allows models to:
- Learn what “normal” looks like per dataset
- Identify deviations that matter because of sensitivity
- Correlate weak signals into meaningful exposure conditions
- Predict which exposure patterns precede real incidents
EAP platforms, by contrast, apply AI to non-data-aware inputs, forcing models to guess at impact without understanding the data itself.
From Exposure Intelligence to Continuous Control
Because DASM understands data risk, it can enforce policy meaningfully.
Exposure intelligence flows into:
- SOAR workflows
- ITSM remediation
- Zero Trust API–driven enforcement
- CTEM decision loops
This closes the gap between:
Insight→ Decision→ Control
Without this loop, exposure assessment remains academic.
Conclusion: Why Data-Focused CTEM Is Non-Negotiable
Exposure assessment platforms were not built to understand data risk—and AI cannot fix what the data model omits.
As long as exposure tools lack:
- Data sensitivity
- Classification
- Behavioral context
- Overexposure and over-permission signals
They will never arrive at a true data risk assessment—only increasingly complex approximations of reachability.
Data Attack Surface Management (DASM) represents a necessary evolution in CTEM:
one that measures exposure where attackers operate, evaluates risk based on impact, and enforces controls where it matters most.
Measuring exposure is easy.
Reducing data risk requires understanding the data.
Featured Resources

Mastering Cybersecurity Insurance Negotiations: A Comprehensive Guide

Navigating the Digital Menace: A Beginner’s Guide to Ransomware
