APIs vs MCP Servers
- Date: May 13, 2026
- Read time: 8 minutes

What’s the Difference and Why It Matters for Modern Infrastructure
Most enterprise systems expose APIs. If you’ve worked with storage, security tools, or cloud platforms, you’ve used them to automate tasks or connect systems. So when something like an MCP (Model Context Protocol) server shows up, the obvious question is: Isn’t this just another API? Well, not quite.
In this post, we’ll break down where APIs end and where MCP servers begin to make a difference, using practical examples aligning to Disaster Recovery along the way.
Let’s start here…
What is an API (in simple terms)?
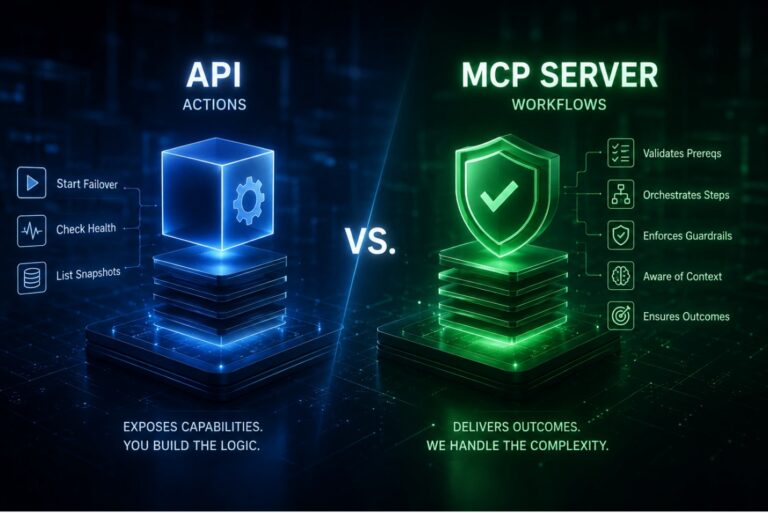
An API (Application Programming Interface) is a way for one system to talk to another. A simple way to think about it is that it gives you a set of remote actions you can trigger.
Examples from the Disaster Recovery (DR) space:
- Start failover
- Check system health
- List snapshots
Each call does one clearly defined task. Nothing more.
What APIs Are Good At
APIs work well because they:
- Expose system capabilities
- Enable automation
- Allow different tools to integrate
Without them, modern infrastructure would be far more manual and fragmented.
Where APIs Start to Break Down
As it pertains to APIs, the limitation isn’t capability. It’s responsibility. APIs give you building blocks, but they stop there.
They Don’t Orchestrate
Real operations are multi-step and conditional. Take DR again, as an example. A typical workflow looks more like this:
- Validate replication health
- Confirm a clean recovery point
- Check system readiness
- Execute failover
- Verify application access
APIs cover each step individually. What they don’t provide is the logic between them. You still need to decide:
- The correct order
- What conditions must pass before moving forward
- How to handle partial failure
In practice, this logic ends up scattered across scripts, pipelines, or runbooks. That’s where things get fragile, especially under pressure.
They Lack Context
Most APIs are stateless. They execute a request and return a result, but they don’t understand the broader situation. For example, an API won’t tell you:
- If a failover is actually safe right now
- Whether your data is in a usable state
- How close you are to meeting recovery objectives
They respond to commands. They don’t help you decide if you should run them.
They Push Complexity to You
Every team ends up building its own layer on top:
- Scripts
- Runbooks
- Automation pipelines
That flexibility is useful, but it comes with tradeoffs:
- Different teams solve the same problem in different ways
- Logic drifts over time
- Maintenance becomes a constant cost
It works, but it rarely stays clean.
APIs Expose Power. MCP Adds Guardrails.
Another important distinction is control.
Traditional APIs often expose every supported action directly. If a system allows snapshot deletion, replication changes, or failover execution, the API typically exposes those operations as-is.
That flexibility is powerful, but it can also create operational risk in disaster recovery environments.
For example:
- You may want failover operations available
- But disable deletion of writable snapshots
- Or restrict destructive recovery actions during testing
With APIs alone, those restrictions usually need to be enforced externally through IAM policies, custom middleware, or additional scripting.
An MCP server can provide an additional operational control layer by limiting which tools and workflows are exposed in the first place.
That allows organizations to enable only approved operations, restrict high-risk actions, and reduce the chance of dangerous automation mistakes during critical events
What is an MCP Server?
An MCP server sits above APIs and packages them into something more usable.
Instead of exposing raw actions, it exposes workflows that already include sequencing, validation, and guardrails.
Put more simply, an MCP server is a control layer that turns APIs into repeatable, context-aware workflows.
Key Differences: API vs MCP
| Differences | API | MCP | Commentary |
| Functions vs Workflows | Trigger failover | Execute a validated failover workflow | The gap is everything around the action: Preconditions Ordering Safety checks Those details are where most failures happen, and MCP handles them by design. |
| Flexibility vs Opinionated Design | Maximum flexibilityYou define the process | Opinionated structureBuilt-in best practices | This tradeoff matters. You give up some flexibility, but you avoid rebuilding the same logic over and over. |
| Building vs Using | You are assembling the system | You are using a system that already encodes how it should run | That distinction shows up quickly in implementation time and reliability. |
A Real Example: Disaster Recovery
To make this concrete, compare how DR automation typically plays out.
Using APIs
You might:
- Call an API to check replication
- Call another to validate snapshots
- Trigger failover
- Add retry logic
- Handle edge cases and errors
This works, but it takes engineering time and ongoing care. It also means your DR process is only as good as the scripts behind it.
Using an MCP Server
You call: Run validated failover
The MCP server coordinates and validates:
- Preconditions
- Execution order
- Safety checks
- State awareness
The outcome is more consistent, and the setup is faster. The tradeoff is that you operate within the model the MCP provides.
Why This Matters
Systems are getting more interconnected and harder to reason about during failures.
In areas like disaster recovery, small mistakes compound quickly. A missed validation or incorrect sequence can turn a recoverable event into a prolonged outage.
APIs give you access. They don’t give you assurance.
What most organizations actually need is confidence that a process will behave correctly when it matters.
The Bigger Picture: From Tools to Systems
APIs made infrastructure programmable. MCP servers move things a step further by making those programmable pieces behave like a system:
- Operational
- Repeatable
- Consistent across environments
It’s the difference between having components and having something that reliably runs end to end.
Where LLMs Fit In
Another reason MCP is gaining attention is its alignment with AI-assisted operations.
Large Language Models (LLMs) are increasingly being used to assist with operational workflows and decision-making. But LLMs still require structured and controlled access to infrastructure systems. This is where MCP becomes especially useful.
Instead of exposing raw APIs directly to an LLM, MCP exposes governed tools and workflows that the model can reason about safely.
For example, during a DR event an LLM-assisted workflow could:
- Check replication health
- Review active alarms
- Validate recovery readiness
- Determine whether failover conditions are safe
- Execute an approved recovery workflow
The important distinction is that the LLM is not inventing actions on its own. It is reasoning over approved workflows and operational context already exposed through the MCP layer.
Bringing This to Cyberstorage
In storage and data protection:
- APIs expose actions like snapshot, replicate, and failover
- MCP connects those actions into larger workflows, such as:
- Security response flows
- Disaster recovery automation
- Continuous validation processes
This becomes critical in cyber resilience. Recovery isn’t just about whether you can fail over. It’s about whether the result is correct and usable.
Introducing MCP for Superna Disaster Recovery Edition
Superna’s Disaster Recovery Edition already includes:
- Automated failover and failback
- Continuous readiness validation
- Orchestrated recovery workflows
Our MCP server builds on that by making those capabilities:
- Programmable
- Easier to integrate with other systems
- Consistent across environments
Instead of building and maintaining custom DR logic, teams can rely on a structured control layer that already encodes how recovery should run.
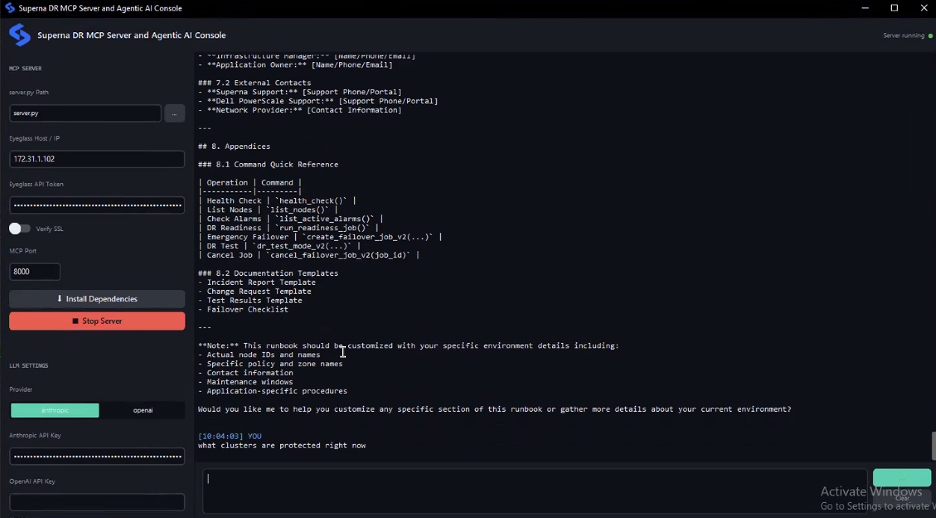
More specifically, the MCP for Disaster Recovery Edition surfaces the Eyeglass DR system as a set of usable, real-time workflows and operations:
System Monitoring and Health
- Check overall system health
- Monitor active alarms
- Review historical alarms to understand past issues
Infrastructure Management
- List managed clusters and nodes
- Retrieve cluster configuration and status
- Monitor SyncIQ policies with DR readiness context
- Review access zones and failover readiness
- Check IP pool configurations for failover scenarios
Disaster Recovery Operations
- Execute controlled or emergency failovers
- Track active and completed failover jobs
- Access detailed job logs for troubleshooting
- Cancel running jobs when needed
DR Testing and Validation
- Enter or exit DR test mode for validation
- Run non-disruptive rehearsal jobs
- Perform full readiness assessments
Configuration Management
- Manage configuration replication between sites
- Update or disable replication jobs as needed
All of these operations run against the live Eyeglass appliance. The MCP server queries the system in real time rather than relying on cached data, which matters during an actual incident when stale information leads to bad decisions.
Learn More
If you want to see how this works in practice, check out the MCP server for Disaster Recovery Edition: https://github.com/Superna-io/DR-MCP
Final Thought
APIs are foundational, but they stop at exposing capability. MCP servers build on that foundation by adding:
- Workflow structure
- Operational context
- Guardrails
- Repeatable execution
And when combined with AI-assisted reasoning systems, MCP provides a more controlled and operationally safe way to automate complex infrastructure workflows without exposing unrestricted infrastructure operations directly.
In environments like disaster recovery, where correctness matters as much as automation, that distinction becomes increasingly important.
Related Articles – MCP + Agentic AI: The Missing Layer in Modern Disaster Recovery
Featured Resources

Mastering Cybersecurity Insurance Negotiations: A Comprehensive Guide

Navigating the Digital Menace: A Beginner’s Guide to Ransomware
